
I'm currently a Junior at Stanford focused on building AI systems that work reliably in the real world. Right now, I'm thinking about how to design robust evaluations for complex agent harnesses. Previously, I worked on the ML Research Team at Lambda Labs on multimodal pretraining, and at the Stanford AI Lab on interpretability. I also serve as the President of the Stanford AI Club, where we've hosted awesome speakers like Sam Altman, Jeff Dean, Guillermo Rauch, and more.
On the side, I love to cook! I run a supper club at Stanford and keep a log of what I cook at @sizzle_with_jason on Instagram.
Featured Projects
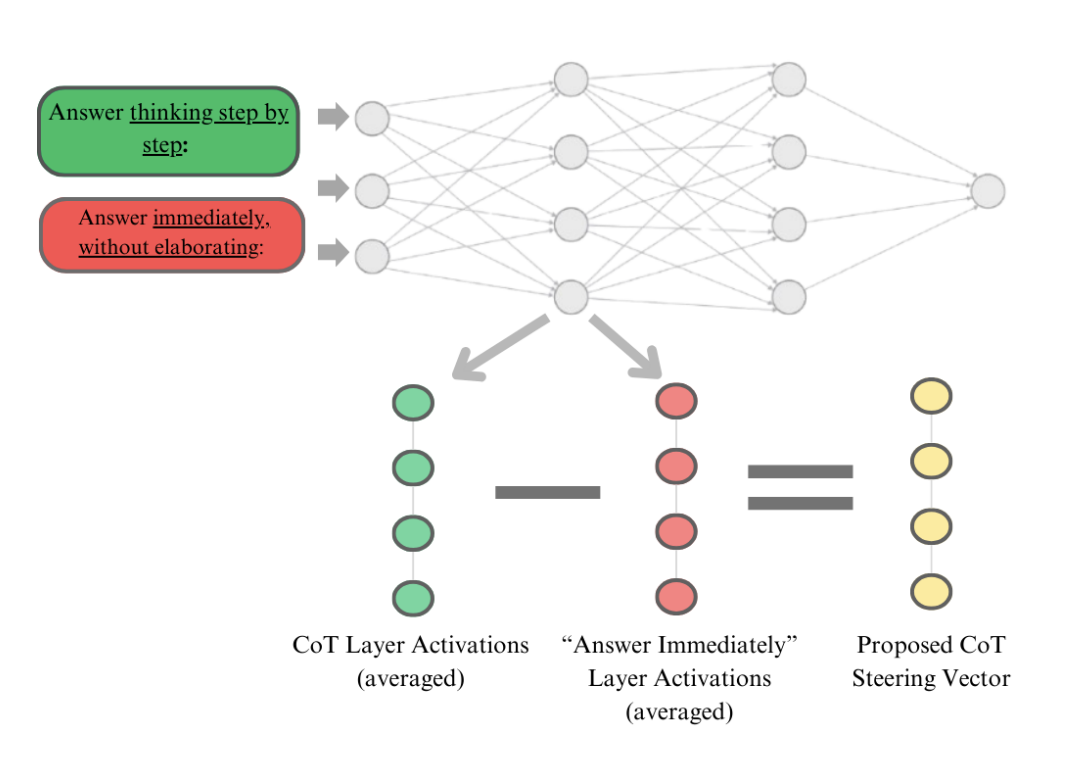
Uncovering Latent CoT Vectors in Language Models [ICLR-W 2025]
Applied Steering Vectors towards Chain of Thought Thinking. Show that steered systems can be steered towards CoT structure while maintaining competitive performance on reasoning benchmarks. Read here!

Improving Controllability of Text-to-Video Generation Through Image Editing and Interpolation
Built a modular text-to-video editing pipeline for Stanford's CS131 Class using iterative keyframe editing and frame interpolation. Achieved near SoTA on VBench against models like Luma and Sora while also enabling intuitive editing. Check it out here!
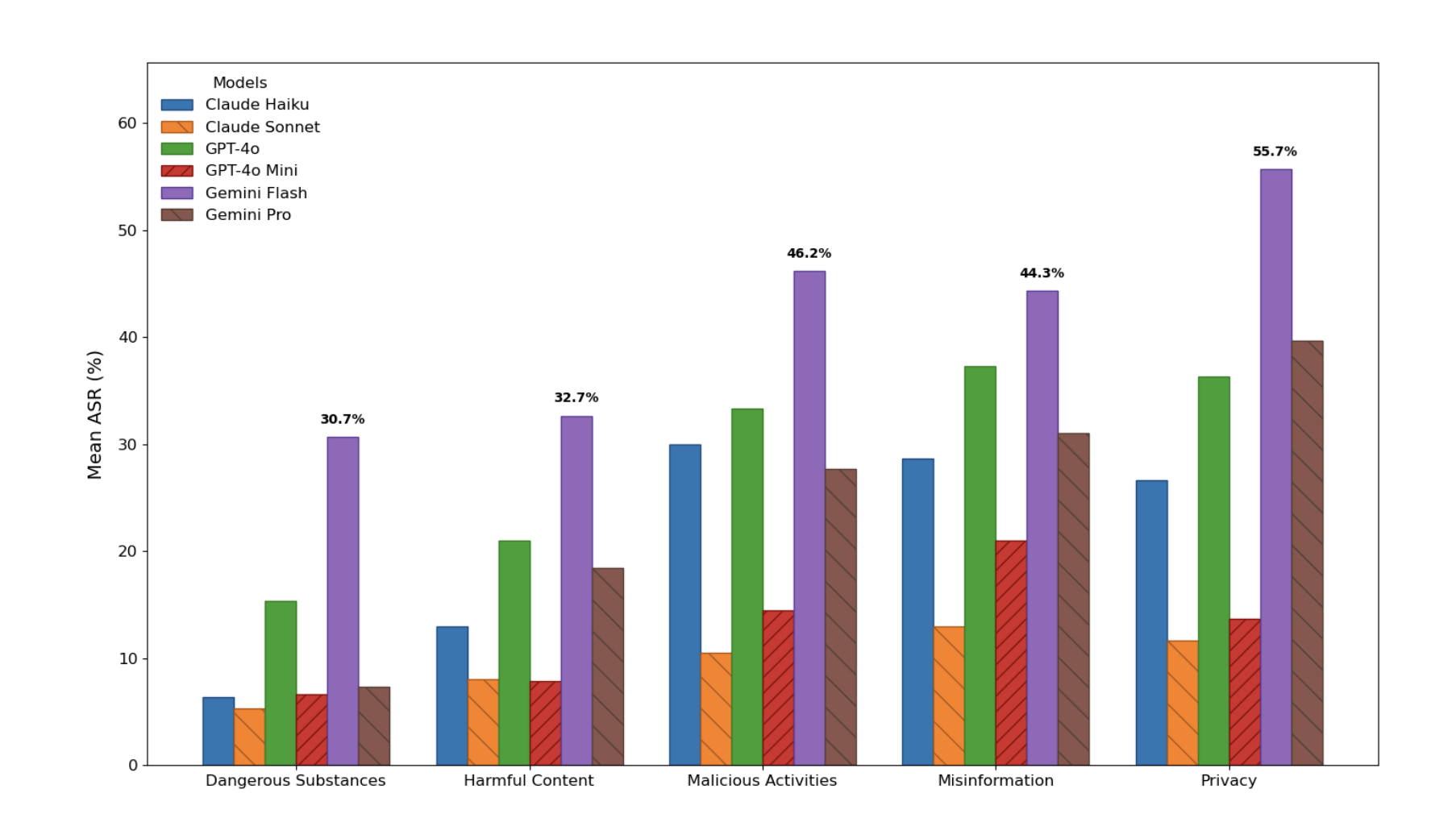
The Structural Safety Generalization Problem [ACL Findings 2025]
Introduce new subclass of AI Safety problems - failure of current safety techniques to generalize over structure, despite semantic equivalence. Read here.
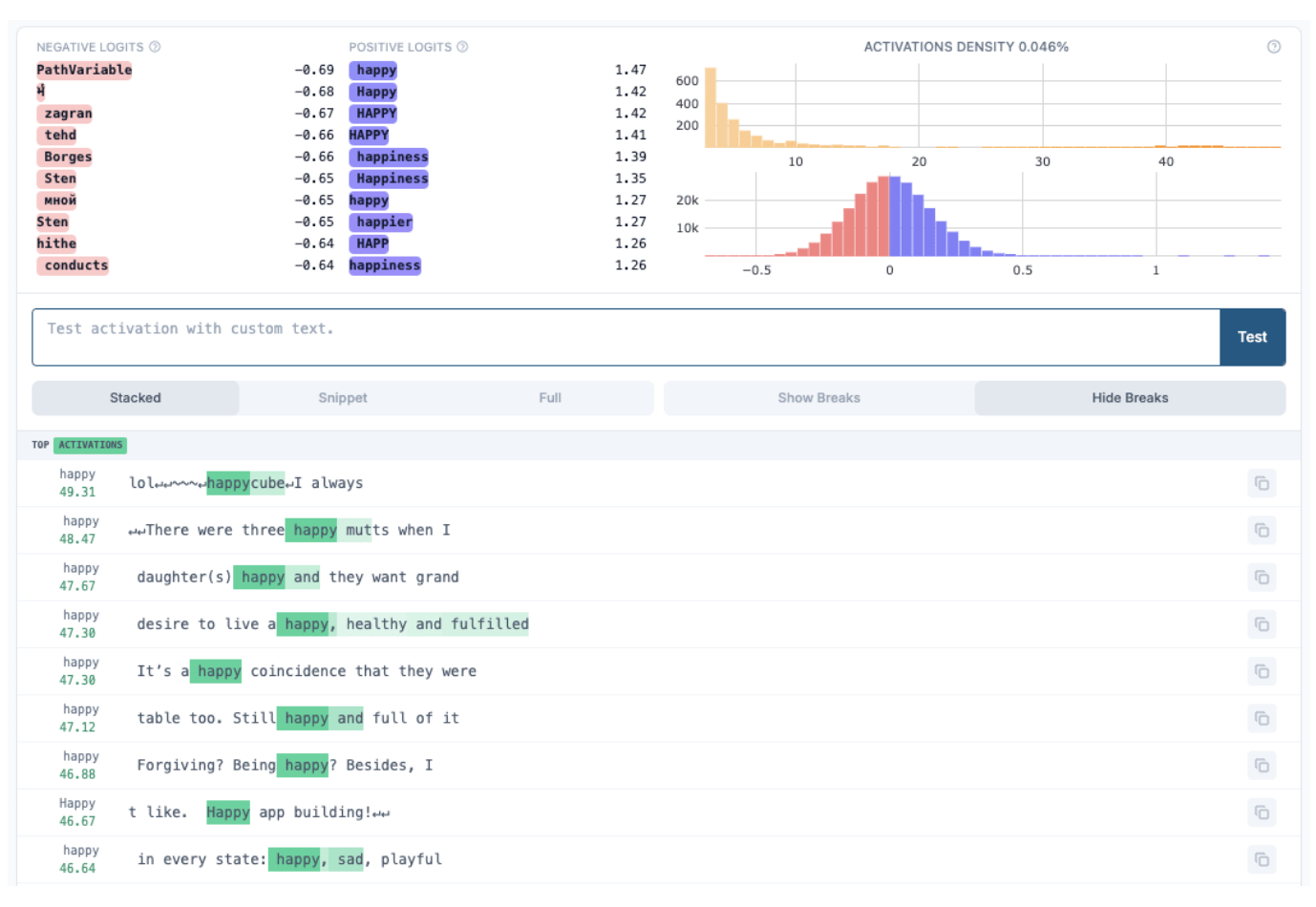
Empirical Insights into Feature Geometry in Sparse Autoencoders (LessWrong)
Interpretability Research with Sparse Autoencoders (SAEs) conducted under Zhengxuan Wu in Chris Pott's Lab. present the first demonstration of the lack of geometric relationships between semantically related concepts in the Feature Space of SAEs. Read here.
Writing
How to Build Intuition in AI
December 11, 2025
Having strong intuition and "feel" on ML concepts is a non-negotiable prerequisite for being productive in ML research. But how do you build it? In this post I share 3 pitfalls I've made in my journey, as well as the current 3-step framework I've arrived at that I find to be most effective (and fun!) for building a robust, practical intuition in AI/ML.
Building Better Benchmarks: We Need Standardized AI Evaluation
December 11, 2024
AI benchmarking is in a state of disarray. From data leakage to reproducibility issues, our current evaluation methods raise serious questions about how we measure AI capabilities. This post explores the limitations of today's benchmarks and proposes a unified set of best practices for moving forward.